ACID in verteilten Systemen
30.07.2010 Permalink In verteilten Systemen (a.k.a SOAs) braucht das Thema Datenkonsistenz erschreckend mehr Aufmerksamkeit als in einem System ohne Verteilung, das sich einer ausgereiften Datenbank bedienen kann.Datenkonsistenz? Da erinnern wir uns doch mal schnell an die Informationssysteme Vorlesung und das strapazierte Beispiel von der Überweisung eines Geldbetrags zwischen zwei Konten. Die Überweisung ist nur dann korrekt ausgeführt, wenn beiden Konten jeweils ein Buchungseintrag hinzugefügt wurde, nämlich eine Belastung auf dem Quellkonto und eine Gutschrift auf dem Zielkonto. Führt ein Fehler dazu, dass z.B. die Gutschrift auf dem Zielkonto fehlt, obwohl die Belastung auf dem Quellkonto vorhanden ist, dann ist -- den Daten zufolge -- Geld "verschwunden". Das widerspricht offensichtlich der beabsichtigten Realität, d.h. es gibt eine Inkonsistenz. Und selbst wenn beide Einzelbuchungen erfolgen, kann eine Abfrage, die zeitlich dazwischenkommt, ein -- so nicht reproduzierbares -- inkonsistentes Bild hervorbringen.
Datenbanktransaktionen und das ACID Paradigma sind in einem nicht-verteilten System das geeignete Mittel, die typischen vier Anomalien (Lost update, Dirty read, Non-repeatable read und Phantom read) zu verhindern und Fehlern in Teilen mit Rückabwicklung des Ganzen zu begegnen (a.k.a Rollback). In einem verteilten System hingegen haben wir möglicherweise mehrere Datenbanken, und wenn sich dann eine aus fachlicher Sicht geschlossene Operation über mehrere Teilsysteme erstreckt, wobei Zugriffe auf die jeweiligen Datenbanken stattfinden, dann reichen uns die so bequemen Datenbanktransaktionen innerhalb der beteiligten Teilsysteme nicht mehr aus.
Nehmen wir als Beispiel eine Reisebuchung. Sie besteht aus drei Einzelbuchungen, die bei unterschiedlichen Unternehmen stattfinden, denn wir benötigen für unsere Reise ein Hotel, einen Flug und einen Mietwagen. Wir stellen uns die Reise in einem Webportal zusammen, geben unsere Kreditkartendaten ein, und drücken auf den "Jetzt alles verbindlich buchen!" Knopf. Was wir hier benutzen, ist ein verteiltes System, das aus wenigstens fünf Teilsystemen besteht. Das Webportal muss für die Reise an jedes der drei Buchungssysteme eine Nachricht schicken, und unsere Kreditkarte wird durch eine weitere Nachricht an den Server des Kreditkartenunternehmens belastet. Aus Benutzersicht handelt es sich um eine geschlossene Operation. Mit einem Flug ohne Hotel und Mietwagen ist uns wahrscheinlich nicht geholfen. Und eine Belastung unserer Kreditkarte ohne eine einzige erfolgte Buchung wäre sehr ärgerlich.
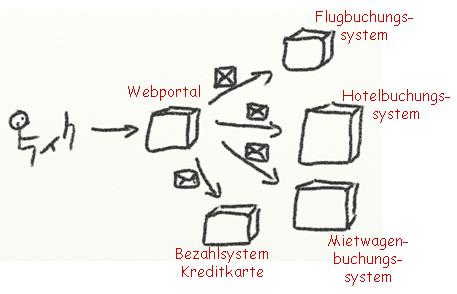
Wir erwarten also bestimmte transaktionale Eigenschaften, aber in diesem Beispiel längst nicht alle vier. Wir hätten gerne A(tomicity), also Ganz-oder-Gar-nicht. Für C(onsistency), also dass unsere Kreditkarte nur um den Betrag belastet wird, der auch tatsächlich den erfolgreichen Buchungen entspricht, wären wir auch dankbar. Auf I(solation) können wir dagegen verzichten. Aber D(urability), also dass die beteiligten Systeme unsere Buchungen nicht zwei Stunden später wieder "vergessen" haben, ist uns wieder sehr wichtig.
Ein Ansatz, der uns bei der Datenkonsistenzwahrung in verteilten Systemen viel Komfort verspricht, sind verteilte Transaktionen, z.B. realisiert durch ein 2PC Protokoll und überwacht durch einen zentralen Transaktionskoordinator. Um diesen einzusetzen bedarf es aber einiger starker Voraussetzungen:
- die beteiligten Teilsysteme "sprechen" das Protokoll
- die zeitlich enge Kopplung ist akzeptabel
- die Kosten durch Lizenzanschaffung und Betrieb des hochverfügbaren Koordinators sind tragbar
a) und b) sind meist nicht sicherzustellen, speziell im SOA Umfeld gilt "loose coupling", womit auch zeitliche Entzerrung durch Asynchronität gemeint ist, als Erfolgsfaktor bei der technischen Realisierung. Kurz: in der Praxis müssen wir i.d.R. auf verteilte Transaktionen verzichten.
Die Konsequenz ist, dass wir uns selbst wieder um Datenkonsistenz Gedanken machen müssen. Konkret bedeutet das zweierlei: erstens sollten wir solchen Entwurfsgrundsätze folgen, die das generelle Problem mildern, und zweitens müssen wir diejenigen Interaktionen zwischen Teilsystemen identifizieren, die bei Fehlschlägen oder durch fehlende Isolation Inkonsistenzen verursachen können. Langlaufende fachliche Transaktionen sind dafür gute Kandidaten. Für jedes einzelne Inkonsistenzrisiko müssen wir uns dann eine Lösung überlegen.
Mühsam, oder? Genau. Aber niemand hat behauptet, dass der Bau verteilter Systeme ein Kinderspiel ist. Der Rest dieses Textes beleuchtet einige praktikable Lösungsideen im Hinblick auf die Eigenschaften des ACID Paradigmas, die wir uns damit ein bißchen zurückerobern können.
Entwurfsgrundsatz: Zustandsminimierung
Je weniger Teilsysteme ihren eigenen Datentopf pflegen, desto weniger
Inkonsistenzen sind zu erwarten. Im -- aus Konsistenzgesichtspunkten -- idealen
Fall gibt es im Gesamtsystem nur eine Datenbank, die von einem Teilsystem
verwendet wird. Aus Gesichtspunkten der Robustheit und Performanz ist das
natürlich nicht sehr günstig, und in dem obigen Reisebuchungsszenario ohnehin
unerreichbar. Wenn wir aber ohne größere Schmerzen aus zwei oder mehr
Datentöpfen einen machen können, ist das sicher ein Gewinn.
Entwurfsgrundsatz: Transaktionale Teilsysteme
Wenn ein Teilsystem nach Bearbeitung eines synchronen Requests den Erfolg
vermeldet, oder asynchron die Nachrichtenentnahme aus einer Queue durch Commit
bestätigt, dann muss es alle seine lokal nötigen Operationen erfolgreich
abgeschlossen haben. Gilt diese Implikation bei allen Teilsystemen, dann haben
wir eine wichtige Voraussetzung für mehr Verlässlichkeit.
Entwurfsgrundsatz: Idempotenz
In einem verteilten System muss ein Client bei asynchroner Kommunikation, die
keine Zustellgarantie z.B. durch ein MOM bietet, mit Nachrichtenverlust rechnen.
Selbst wenn die Zustellung garantiert funktioniert hat, kann der Client während
der Ausführung nachfolgender Interaktionen abstürzen, und damit "vergessen",
welche Nachrichten bereits erfolgreich zugestellt oder sogar bearbeitet wurden.
Kurz: wir müssen damit rechnen, dass die gleiche fachliche Nachricht n-mal an
ein Teilsystem übermittelt wird. Es ist daher eine enorme Entlastung, wenn jedes
Teilsystem sich bzgl. der empfangenden Nachrichten idempotent verhält, also die
2te bis n-te Nachricht keine Wirkung auf den Empfänger mehr hat. Idempotenz muss
je nach Art der Operationen gesondert "eingebaut" werden. So sind lesende
Zugriffe ohne weiteres Zutun idempotent, genauso wie das Setzen von Werten. Das
Hinzufügen oder Löschen von Geschäftsobjekten ist von sich aus erstmal nicht
idempotent.
Kompensation
Atomarität bedeutet, dass entweder alle Interaktionen zwischen Teilsystemen
ausgeführt wurden oder gar keine. Da im Verlauf einer Transaktion bis zur
letzten Interaktion mit einem Fehler gerechnet werden muss, müssen wir eine
Möglichkeit haben, alle bisher erfolgreichen Aktionen "zurückdrehen" zu können.
Dieses "Zurückdrehen" kann nur durch Versendung kompensierender Nachrichten
erfolgen. Im o.g. Reisebuchungsbeispiel muss daher zu jeder Buchungsoperation
auch eine Stornooperation existieren. Hierbei kommt es uns nun zugute, dass
unsere Teilsysteme für sich transaktional zuverlässig arbeiten.
Der Koordinator der langlaufenden Transaktion muss also Buch führen, was bereits ausgeführt wurde, und bei einem Fehler mechanisch mit einer (umgedrehten) Folge von Kompensationen reagieren. Da diese Funktionalität gut generalisierbar ist, wird die Ausführung solcher Prozesse gerne an Workflow- oder BPEL-Server übertragen, die zudem auch eine Überwachung von z.B. über Tage laufende Prozesse ermöglichen.
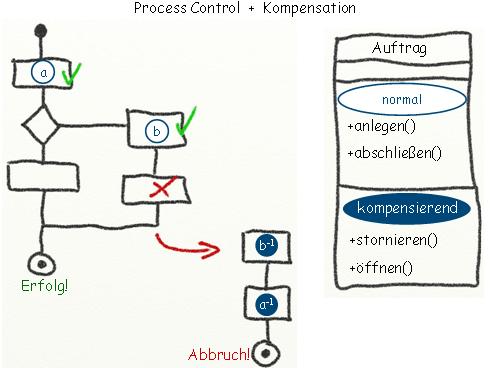
Mittels Kompensation und transaktionalen Teilsystemen erreichen wir so immerhin A(tomicity) und D(urability). C(onsistency) wird dadurch aber noch nicht durchgehend gesichert.
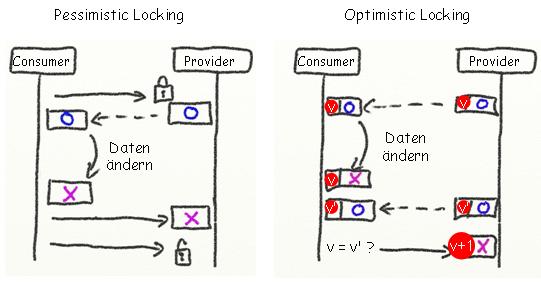
Versionszähler (a.k.a Optimistic Locking)
Im Rahmen einer langlaufenden Transaktion kann es erforderlich sein, ein
Geschäftsobjekt zu Beginn über ein Teilsystem zu lesen, dieses im Laufe des
Bearbeitungsprozesses zu verändern, und es schließlich geändert an das
entsprechende Teilsystem zurückzugeben. Was ist, wenn es konkurrierende
Bearbeitungsprozesse gibt, die das gleiche Geschäftsobjekt verändern? Wir stehen
vor einem Lost update.
Um Daten vor konkurrierenden Änderungen zu schützen, gibt es zwei Techniken: Sperren und Versionszähler. Gerade in der unvorhersagbaren Welt verteilter Systeme sind Sperren selten sinnvoll. Sie behindern Parallelität (und damit mindern sie Durchsatz), und sie könnten Datensätze unakzeptabel lange blockieren, wenn z.B. der Prozess, der die Sperre angefordert hat, "verstorben" ist. Daher wird statt eines Sperrvermerks ein Versionszähler zu betroffenen Geschäftsobjekten hinzugefügt. Stimmt die Version, die kurz vor Abschluss des Prozesses im Geschäftsobjekt zu finden ist, nicht mehr mit der überein, die zu Beginn des Prozesses gelesen wurde, kann man auf einen Störenfried schließen, der offensichtlich schneller war... und muss den Verlierer dieses Wettlaufs zurückrollen. Dadurch erhalten wir aber ein gutes Stück C(onsistency).
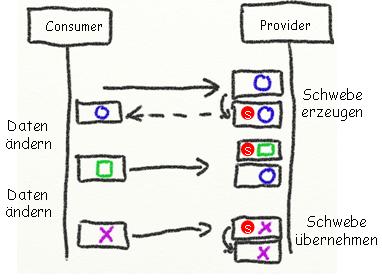
Schwebeverarbeitung
Bisher gab es keine Isolation langlaufender Transaktionen. Es fehlt also die
Illusion, dass sie nacheinander statt nebeneinander ablaufen. Im
Reisebuchungsszenario ist diese Eigenschaft verzichtbar, bei der Bearbeitung
bspw. eines Versicherungsvertrags möchte man aber während des
Bearbeitungsprozesses verhindern, dass mit der unsauberen Fassung gearbeitet
wird. Wir fürchten also ein Dirty read, und verlangen Isolation.
Hier hilft uns eine simple Idee, die mir als "Schwebeverarbeitung" bekannt ist. Der Bearbeitungsprozess erzeugt zunächst eine Kopie des Geschäftsobjekts, die sogenannte "Schwebe". Alle Operationen richten sich an diese Schwebe, und erst der fachliche Abschluss führt zur Ersetzung des bisherigen Originals durch den Stand der Schwebe. Diese Idee bringt uns I(solation) im Bezug auf das betroffene Geschäftsobjekt. Sollte man mehrere Geschäftsobjekte in verschiedenen Teilsystemen bearbeiten müssen, so ist die Schwebeverarbeitung in allen Teilsystemen zu implementieren.
Aus den Lösungsideen geht zum einen hervor, dass wir nicht auf Konsistenz verzichten müssen. Es wird aber auch deutlich: die Anstrengungen, die man für transaktionale Eigenschaften in verteilten Systemen unternehmen muss, können beachtlich sein. Unnötige Verteilung, weil es gerade en-vogue ist, verbietet sich daher. Dort, wo Verteilung unvermeidlich ist, können wir uns meistens genügend ACID erkämpfen, um der Fachlichkeit gerecht zu werden. Mit ziemlicher Sicherheit werden Fachbereichler bzgl. ACID schnell maximale Ansprüche stellen. Dann muss der Softwarearchitekt zusammen mit Fachbereichlern und Projektleitung Kompromisse aushandeln, denn er muss auch Entwicklungskosten, Performanz, Robustheit und Wartbarkeit im Auge behalten.